♦ 🐆 3 min, 🐌 7 min
Automatic web page deployment
- tags: dev ops, git, python, web development
- production page files should be under version control so we can role back at any time
- on server we want to have only the files needed for the production page
- deployment process should be as simple as running a set of
bashcommands:
generate_server_files
get_server_files
clean_server
prepare_server
deploy_server
git and python and we can create a really simple deployment pipeline.Generate server files
The idea is to create apython script that will run all the commands needed to build up a web page. For example the list of commands needed to copy all project files for the server and create a database would be:commands_to_execute = {
"copy_django_app": {
"command": "cp",
"initial_location": web_page_location,
"file": "user_site/*",
"final_location": page_files_location
},
"copy_server_files": {
"command": "cp",
"initial_location": web_page_location,
"file": "server_setup/",
"final_location": page_files_location + "/server_setup"
},
"generate_database": {
"command": "python3",
"parameters": manage_py_script + " migrate"
}
}
execute_commands(commands_to_execute)
page_files:page_files:
|-blog
|---static
|-----css
|-----img
|---templates
|-server_setup
|---nginx
|---uwsgi
page_files folder contains all the files needed for the web page and the server. How uwsgi is configured, how nginx is configured. Next thing is to put all of the new page_files under git so we can role back to any production version at any moment. For that I use a special git branch named page_files.Pro tip: if you won't to avoid getting certain files to the production server use rsyn with --exclude='file_name' flag instead of cp.How to create an empty git branch?
First thing's first we need to create an empty git branch since we don't want anything other then page_files in it. So to create a branch that doesn't inherit from master or any other branch we use --orphan option:git checkout --orphan
git reset
.gitignore file to the folder we want to contain our page_files in and commit it:touch page_files/.gitignore
git add page_files
git commit -m 'creating page_files branch'
git push -u origin
page_files folder. So we go to the root/parent directory of our git project and create another .gitignore file with content:# Ignore everything
*
# Except the .gitignore file and page_files
!.gitignore
!page_files/*
Storing version of page_files as commit:
For each of the versions of page_files we want to know when it was created and the git hash of the code from the master that was used to create it. With some command line magic we get the current timestamp in a desired format:$(\date '+%Y-%m-%d-%H:%M:%S' )"
master branch we can use:git log -n 1 --pretty=format:"%H" master
2019-09-01-16:35:57: Generating page_files with master version e41f6cf1f9a67cfb7c
page_files branch since we don't want the generation files in that branch. So how do we solve this? The cleanest solution I found was to copy generated page_files into a temp folder outside of the git repo. Switch the branch, copy those files in and commit. I know it's ugly but for now it's the best I've got. When we put everything together our bash script generate_server_files.sh will contain:#! /bin/bash
generate_server_files(){
# generate the page_files
python3 generate_web_page.py $1
# move to page_files branch
git checkout page_files
cp -r "$1/page_files" .
# add all changes and commit them
git add .
time_stamp="$(\date '+%Y-%m-%d-%H:%M:%S' )"
hash="$(git log -n 1 --pretty=format:'%H' master)"
git commit -m "$time_stamp: Generating page_files with master version $hash"
git push
# get back to master
git checkout master
}
generate_server_files '~/junk_yard'. Alright files are online let's get them to the server. That's how the server version should look like 🙂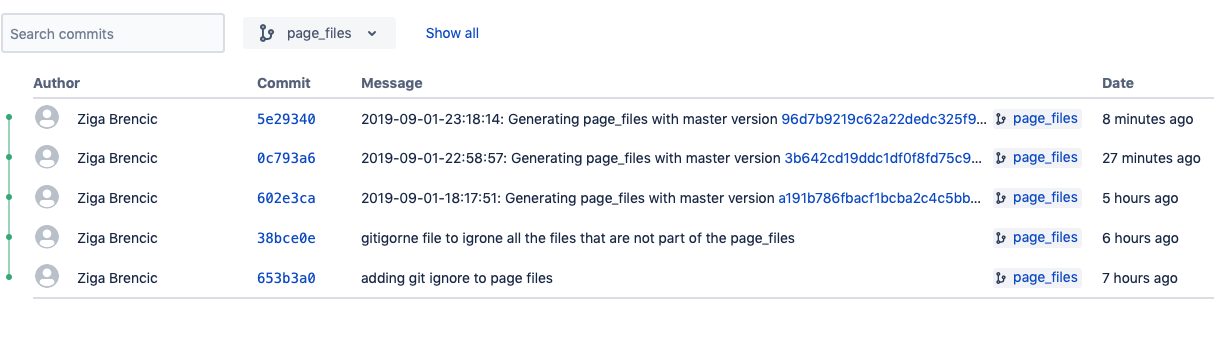
How to pull just a single git branch?
In the get_server_files part we pull from the remote server only one desired git branch. We can do this with:git clone -b --single-branch REPOSITORY
--depth=1 so we pull from the server only the latest commit. We want to deploy the last version of software unless needed otherwise:git clone -b page_files --depth=1 --single-branch REPOSITORY
Server deployment
I have a set ofbash scripts that clean, prepare and deploy the server:clean_server
prepare_server
deploy_server
Get notified & read regularly 👇